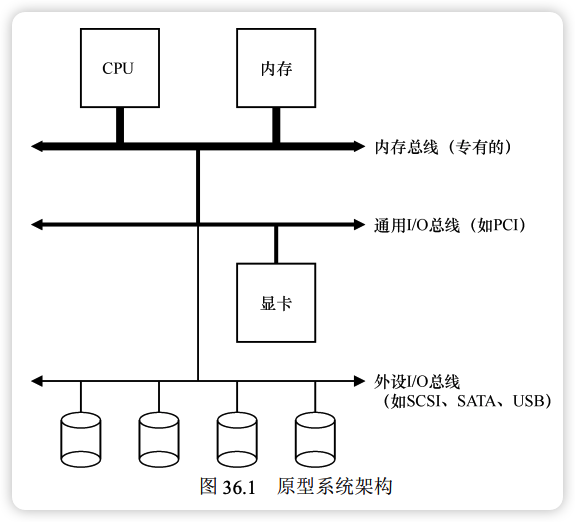
系统架构
典型系统的架构采用分层设计,主要基于物理布局和造价成本的考量。越快的总线越短,高性能总线造价高昂且空间有限。
- 内存总线 (Memory Bus):连接 CPU 与系统内存。
- I/O 总线 (I/O Bus):如 PCI,连接显卡等高性能 I/O 设备。
- 外围总线 (Peripheral Bus):如 SCSI、SATA、USB,连接磁盘、鼠标等低速设备,优势在于可连接大量设备。
标准设备与协议
标准设备包含两部分:向系统展现的硬件接口(供系统软件控制)和内部结构(包含 CPU、内存及特定芯片,负责具体实现)。
简化的设备接口包含三个寄存器:
- 状态寄存器 (Status):读取设备当前状态。
- 命令寄存器 (Command):通知设备执行具体任务。
- 数据寄存器 (Data):传递或接收数据。
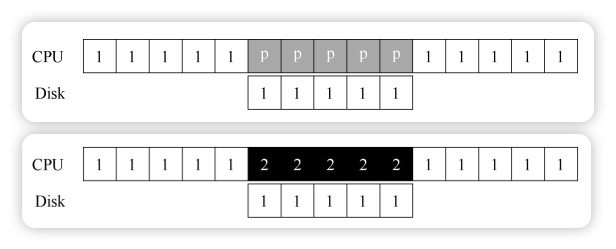
轮询协议 (Polling)
操作系统与设备交互的典型协议如下:
- 等待就绪:反复读取状态寄存器,等待设备进入就绪状态(轮询)。
- 下发数据:将数据写入数据寄存器。如果主 CPU 参与数据移动,称为编程的 I/O (PIO, Programmed I/O)。
- 下发命令:将命令写入命令寄存器,设备开始执行。
- 等待完成:再次轮询状态寄存器,等待设备执行完成。
该协议简单有效,但轮询过程极其低效,在等待设备期间浪费了大量 CPU 时间。
优化机制
中断 (Interrupt)
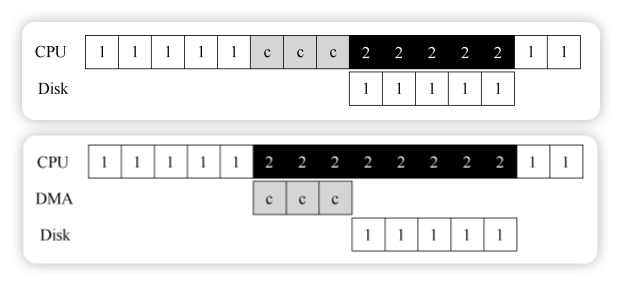
为了减少轮询开销,引入了中断机制。CPU 向设备发出请求后让对应进程睡眠,切换执行其他任务。设备完成操作后抛出硬件中断,引发 CPU 执行中断服务例程 (ISR),结束请求并唤醒等待的进程。
中断允许计算与 I/O 重叠,显著提高 CPU 利用率。但中断并非总是最优解:
- 快速设备:如果设备处理极快,上下文切换和中断处理的开销会超过收益,此时轮询更好。
- 网络设备:网络端收到大量数据包时,频繁中断会导致操作系统发生活锁 (Livelock),无法处理用户请求。此时偶尔使用轮询可以更好控制系统行为。
- 混合策略:先尝试轮询一小段时间,未完成再使用中断(两阶段策略)。
- 中断合并 (Coalescing):设备等待一小段时间,将多次中断合并为一次抛出,降低处理代价。
DMA (直接内存访问)
使用 PIO 方式时,CPU 时间仍会浪费在数据传输上。DMA (Direct Memory Access) 引擎是一个特殊设备,专门协调内存和设备间的数据传递,无需 CPU 介入。
操作系统只需告诉 DMA 引擎数据在内存的位置、大小及目标设备,随后即可处理其他请求。DMA 完成数据传输后会抛出中断通知操作系统。
设备交互方法
操作系统与设备通信主要有两种方式:
- 明确的 I/O 指令:如 x86 上的
in和out指令。这些通常是特权指令,指定存入数据的寄存器和设备端口。 - 内存映射 I/O (Memory-mapped I/O):硬件将设备寄存器映射为内存地址。操作系统通过读写该内存地址来访问设备寄存器。
设备驱动程序
为了实现设备无关的操作系统,底层引入了设备驱动程序 (Device Driver),封装所有设备交互的细节。
以 Linux 文件系统栈为例,文件系统只需向通用块设备层发送读写请求,块设备层将其路由给对应的设备驱动,由驱动完成底层操作。这种抽象隐藏了细节,但也可能导致设备特定的高级功能(如 SCSI 的丰富报错)被通用接口屏蔽。
驱动程序代码占据了 Linux 内核代码的 70% 以上,且由于开发者水平参差不齐,是内核崩溃的主要原因。
案例研究:IDE 磁盘驱动程序
IDE 硬盘接口包含 4 种寄存器:控制、命令块、状态和错误。在 x86 上通过 in 和 out 指令访问特定 I/O 地址(如 0x3F6)。
交互协议包括:等待驱动就绪、写入参数(扇区数、LBA、驱动编号)、开启 I/O(发送读写命令)、数据传送(等待 READY 和 DRQ 后写入数据)、中断处理和错误处理。
xv6 操作系统中简化的 IDE 驱动程序实现如下:
static int ide_wait_ready() {
while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY))
; // loop until drive isn't busy
}
static void ide_start_request(struct buf *b) {
ide_wait_ready();
outb(0x3f6, 0); // generate interrupt
outb(0x1f2, 1); // how many sectors?
outb(0x1f3, b->sector & 0xff); // LBA goes here ...
outb(0x1f4, (b->sector >> 8) & 0xff); // ... and here
outb(0x1f5, (b->sector >> 16) & 0xff); // ... and here!
outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((b->sector>>24)&0x0f));
if(b->flags & B_DIRTY){
outb(0x1f7, IDE_CMD_WRITE); // this is a WRITE
outsl(0x1f0, b->data, 512/4); // transfer data too!
} else {
outb(0x1f7, IDE_CMD_READ); // this is a READ (no data)
}
}
void ide_rw(struct buf *b) {
acquire(&ide_lock);
for (struct buf **pp = &ide_queue; *pp; pp=&(*pp)->qnext)
; // walk queue
*pp = b; // add request to end
if (ide_queue == b) // if q is empty
ide_start_request(b); // send req to disk
while ((b->flags & (B_VALID|B_DIRTY)) != B_VALID)
sleep(b, &ide_lock); // wait for completion
release(&ide_lock);
}
void ide_intr() {
struct buf *b;
acquire(&ide_lock);
if (!(b->flags & B_DIRTY) && ide_wait_ready() >= 0)
insl(0x1f0, b->data, 512/4); // if READ: get data
b->flags |= B_VALID;
b->flags &= ~B_DIRTY;
wakeup(b); // wake waiting process
if ((ide_queue = b->qnext) != 0) // start next request
ide_start_request(ide_queue); // (if one exists)
release(&ide_lock);
}