多级反馈队列(Multi-level Feedback Queue, MLFQ)由 Corbato 于 1962 年提出,并因其在 CTSS 和 Multics 中的贡献获得图灵奖。该调度算法至今仍广泛应用于现代操作系统。
MLFQ 旨在同时解决两个相互矛盾的目标:
核心问题在对进程特征(如运行长度)一无所知的情况下,调度程序如何通过“学习”进程的行为,在减少响应时间的同时优化周转时间?
MLFQ 是利用历史经验预测未来的典型案例:通过观察进程过去的阶段性行为来预测其未来的需求。这种启发式方法虽高效,但需谨慎设计以避免因预测失误导致决策劣化。
基本规则
MLFQ 由多个独立的队列组成,每个队列对应不同的优先级。任何时刻,一个工作只能存在于一个队列中。
MLFQ 的关键在于优先级并非固定,而是根据进程的运行行为动态调整:
- 规则 1:如果 Priority(A) > Priority(B),运行 A(不运行 B)。
- 规则 2:如果 Priority(A) = Priority(B),轮转(RR)运行 A 和 B。
通过这种方式,调度程序在运行过程中“学习”进程特征,利用历史行为预测未来需求。
如何改变优先级
为了区分交互型(短时间、频繁 I/O)和计算密集型(长时间)工作,我们尝试以下规则:
- 规则 3:工作进入系统时,初始化为最高优先级。
- 4a:若工作用完整个时间片,则降低其优先级(移入下一级队列)。
- 4b:若工作在时间片内主动释放 CPU,则优先级保持不变。
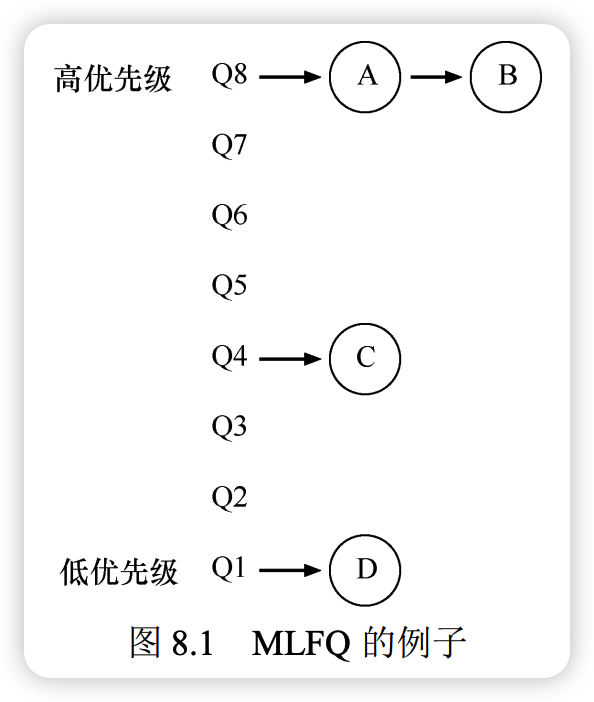
实例 1:单个长工作
当一个长时间运行的工作进入 MLFQ 时,其优先级会随时间逐渐降低:
- 初始状态:工作进入最高优先级队列(Q2)。
- 优先级降级:每耗尽一个时间片,调度程序就将其优先级减 1。
- 最终状态:经过 Q2 和 Q1 的执行后,工作最终降至最低优先级队列(Q0)并保持在该层。
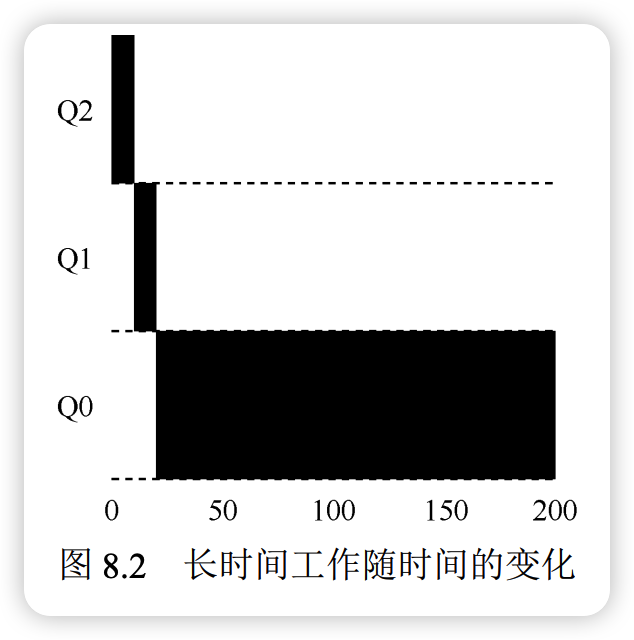
实例 2:加入短工作
MLFQ 通过“先入为主”的假设来逼近最短工作优先(SJF)调度:
- 初始假设:由于系统无法预知工作的运行时间,MLFQ 会默认将所有新工作视为“短工作”,并赋予其最高优先级。
- 动态调整:
- 短工作(如交互型任务):在最高优先级队列中迅速执行完毕,获得极佳的响应时间。
- 长工作(如 CPU 密集型任务):随着运行时间的增加,其优先级会被逐步降低,最终移入低优先级队列。
核心逻辑
实例 3:包含 I/O 操作
根据规则 4b,如果进程在时间片用完前主动放弃 CPU,其优先级将保持不变。
- 设计意图:交互型工作通常包含大量 I/O(如等待用户输入),会在极短时间内放弃 CPU。通过保持其优先级,系统能确保这类任务获得快速响应。
- 运行表现:
- 交互型工作 B:每执行 1ms 即发起 I/O,因其从未耗尽时间片,始终留在最高优先级。
- 长运行工作 A:在低优先级运行,仅在 B 等待 I/O 时获取 CPU。
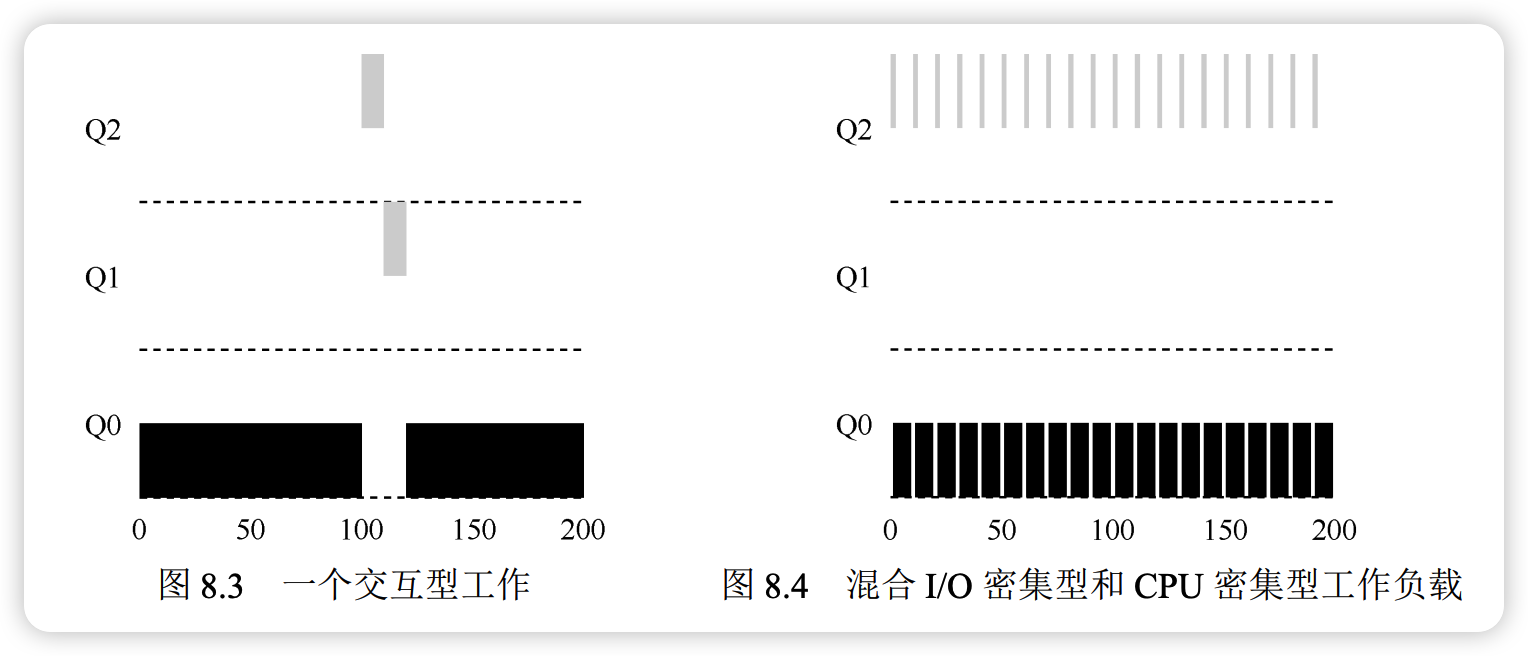
关键点MLFQ 通过“不惩罚主动让出 CPU 的行为”,实现了对交互型工作的优先调度,保障了系统的响应性。
当前 MLFQ 的缺陷
尽管基本算法表现良好,但存在以下严重问题:
- 饥饿问题(Starvation):若系统中有大量交互型工作,它们会持续占用 CPU,导致长工作永远无法运行。
- 欺骗调度程序(Gaming the Scheduler):用户可以编写程序,在时间片用完前(如运行到 99% 时)故意发起一个 I/O 操作释放 CPU,从而非法维持高优先级,独占 CPU 资源。
- 行为改变(Change of Behavior):一个计算密集型工作如果后期转变为交互型工作,在当前规则下它将无法恢复到高优先级。
提升优先级
为了解决饥饿问题并应对进程行为的变化,引入规则 5:
- 规则 5:经过一段时间 ,将系统中所有工作重新加入最高优先级队列。
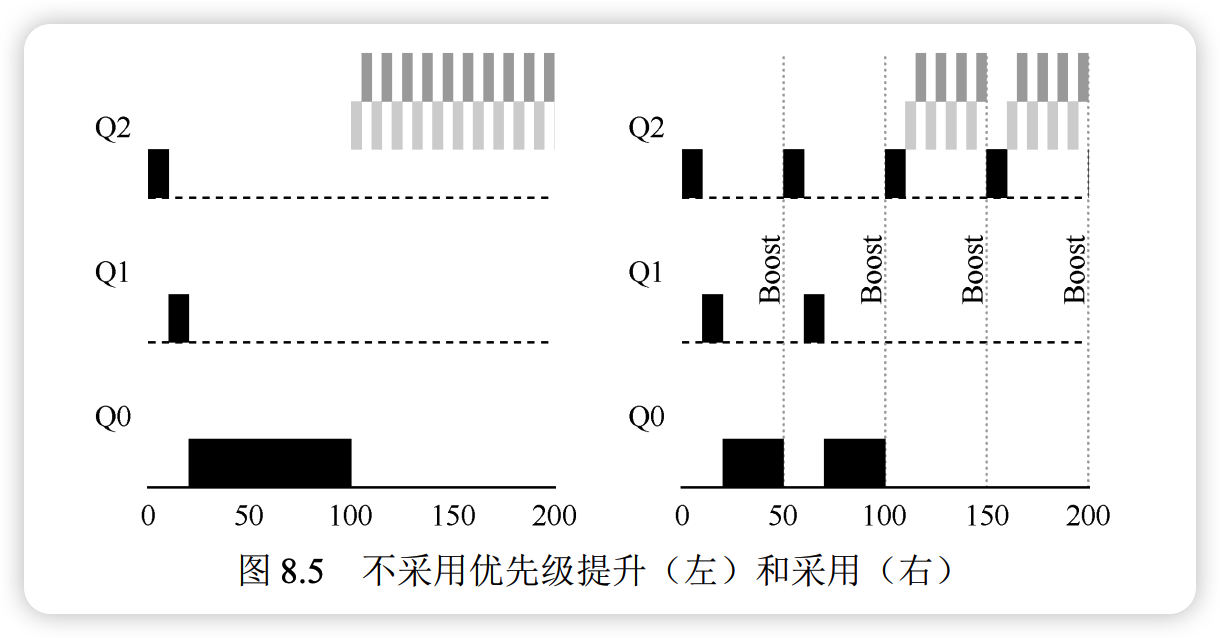
解决的问题
- 避免饥饿:即使是 CPU 密集型长工作,也能定期回到高优先级队列,通过轮转获得执行机会。
- 动态适应:若一个长工作转变为交互型工作,优先级提升能让调度程序重新发现其特性。
周期 的设置是一个难题:
- 太长:长工作仍会面临饥饿。
- 太短:交互型工作的响应时间会受到干扰。
巫毒常量这种需要“黑魔法”才能正确设置的参数被称为巫毒常量。它们通常需要根据经验不断调试,且难以找到一个普适的最优值。
更好的计时方式
为了防止进程通过在时间片结束前发起 I/O 来“愚弄”调度程序(即保留高优先级),需要改进计时机制:
核心思路:不再在每次调度时重新计时,而是记录进程在某一层队列中消耗的累计总时间。
- 规则 4(修订):一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级。
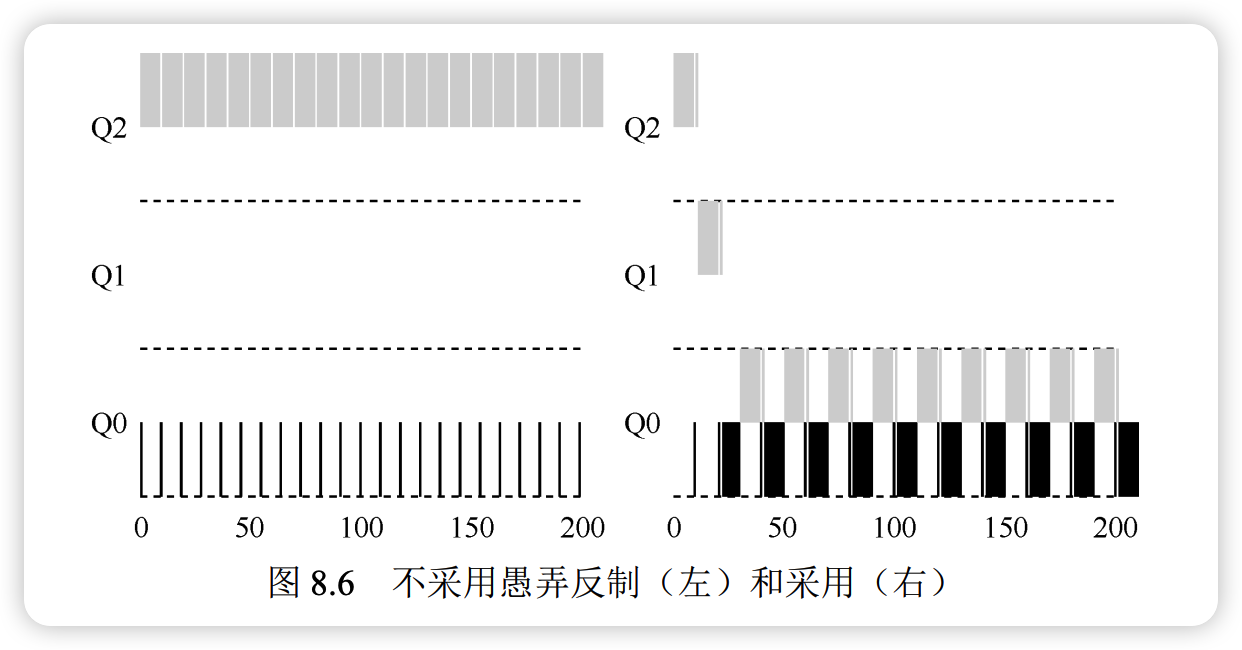
防御恶意行为通过记录累计时间,无论进程如何拆分其 CPU 使用时间(如频繁发起 I/O),只要总用时达到配额,就会被降级。这确保了进程无法通过欺骗手段垄断 CPU,保障了调度的公平性。
MLFQ 调优及其他问题
配置 MLFQ 需要在多个参数间寻找平衡,这些参数通常被称为“巫毒常量”:
- 队列数量:系统应设置多少层优先级?
- 时间片大小:不同队列的时间片应如何分配?
- 提升周期 :多久进行一次优先级提升?
常见的优化策略
- 可变时间片:高优先级队列配置较短时间片(如 10ms),以保障交互响应;低优先级队列配置较长时间片(如 100ms),以减少上下文切换开销。
- 配置表驱动:如 Solaris 系统通过预设的配置表来定义 60 层队列的行为。
- 数学公式驱动:如 FreeBSD 基于 CPU 使用量衰减(decay-usage)公式动态调整优先级。
Ousterhout 定律尽可能避免巫毒常量。如果无法避免,应提供合理的默认值并允许管理员手动调优。
其他特征
- 系统预留:最高优先级通常留给操作系统核心任务。
- 用户建议 (Advice):通过
nice等工具,用户可以干预进程的优先级,影响其获得 CPU 的机会。
总结
多级反馈队列(MLFQ)通过观察进程的历史行为(反馈)来动态调整优先级。它不需要对工作的运行时长有先验知识,却能同时兼顾交互型工作的响应性与 CPU 密集型工作的周转时间。
- 规则 1:如果 Priority(A) > Priority(B),运行 A。
- 规则 2:如果 Priority(A) = Priority(B),轮转(RR)运行 A 和 B。
- 规则 3:工作进入系统时,初始化为最高优先级。
- 规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级。
- 规则 5:经过一段时间 ,将系统中所有工作重新加入最高优先级队列。
策略建议 (Advice)操作系统可以通过
nice(调度)、madvise(内存) 等接口接收用户提供的“建议”,以辅助做出更优的决策。
MLFQ 凭借其出色的自适应能力,成为了类 BSD UNIX、Solaris 以及 Windows 等现代操作系统的基础调度程序。