此前我们已了解进程对 CPU 和内存的虚拟化。本章引入新抽象:线程(thread)。多线程程序拥有多个执行点(PC),它们共享地址空间但拥有独立的寄存器状态。
线程上下文切换类似于进程,需保存状态至线程控制块(TCB),但无需切换页表。
主要区别在于栈:单线程进程仅有一个栈,而多线程进程为每个线程分配独立的栈(线程本地存储),从而改变了地址空间布局(如下图所示)。
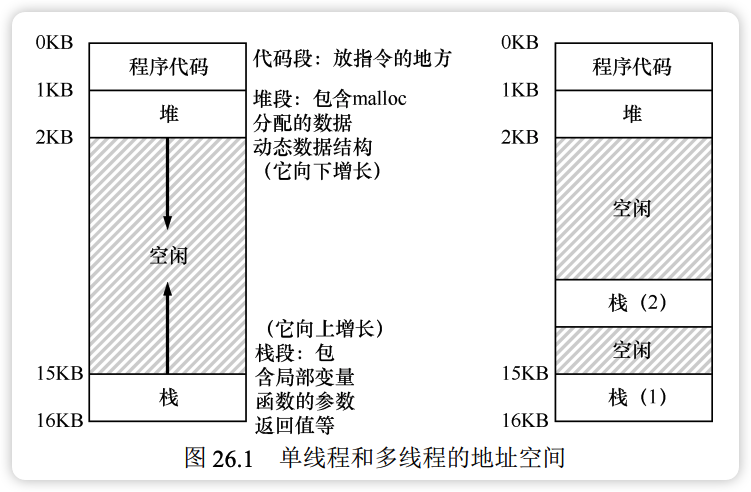
这种多栈布局虽然复杂,但在栈空间通常较小的情况下是可行的。
实例:线程创建
下面的示例代码展示了主程序创建两个线程(T1 和 T2),分别打印 “A” 和 “B”。线程创建后可能立即运行,也可能处于就绪状态,具体取决于调度器。主程序通过 pthread_join() 等待线程完成。
#include <stdio.h>
#include <assert.h>
#include <pthread.h>
void *mythread(void *arg) {
printf("%s\n", (char *) arg);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
int rc;
printf("main: begin\n");
rc = pthread_create(&p1, NULL, mythread, "A"); assert(rc == 0);
rc = pthread_create(&p2, NULL, mythread, "B"); assert(rc == 0);
// join waits for the threads to finish
rc = pthread_join(p1, NULL); assert(rc == 0);
rc = pthread_join(p2, NULL); assert(rc == 0);
printf("main: end\n");
return 0;
}由于调度策略的不确定性,线程的执行顺序多种多样。下表展示了三种可能的执行轨迹(时间向下增加):
| 主程序 | 线程 1 | 线程 2 |
|---|---|---|
| 开始运行 | ||
| 打印 “main:begin” | ||
| 创建线程 1 | ||
| 创建线程 2 | ||
| 等待线程 1 | ||
| 运行 | ||
| 打印 “A” | ||
| 返回 | ||
| 等待线程 2 | ||
| 运行 | ||
| 打印 “B” | ||
| 返回 | ||
| 打印 “main:end” |
| 主程序 | 线程 1 | 线程 2 |
|---|---|---|
| 开始运行 | ||
| 打印 “main:begin” | ||
| 创建线程 1 | ||
| 运行 | ||
| 打印 “A” | ||
| 返回 | ||
| 创建线程 2 | ||
| 运行 | ||
| 打印 “B” | ||
| 返回 | ||
| 等待线程 1 | ||
| 立即返回,线程 1 已完成 | ||
| 等待线程 2 | ||
| 立即返回,线程 2 已完成 | ||
| 打印 “main:end” |
| 主程序 | 线程 1 | 线程 2 |
|---|---|---|
| 开始运行 | ||
| 打印 “main:begin” | ||
| 创建线程 1 | ||
| 创建线程 2 | ||
| 运行 | ||
| 打印 “B” | ||
| 返回 | ||
| 等待线程 1 | ||
| 运行 | ||
| 打印 “A” | ||
| 返回 | ||
| 等待线程 2 | ||
| 立即返回,线程 2 已完成 | ||
| 打印 “main:end” |
线程创建类似于函数调用,但被调用的例程作为独立线程运行,其执行时机不确定(可能在创建者返回之前或之后)。这种不确定性使得并发程序的行为难以预测和理解。
为什么更糟糕:共享数据
简单的线程创建展示了执行顺序的不确定性,而当线程访问共享数据时,情况变得更加复杂。
考虑以下代码:两个线程尝试更新同一个全局共享变量 counter。
#include <stdio.h>
#include <pthread.h>
#include "mythreads.h"
static volatile int counter = 0;
//
// mythread()
//
// Simply adds 1 to counter repeatedly, in a loop
// No, this is not how you would add 10,000,000 to
// a counter, but it shows the problem nicely.
//
void * mythread(void *arg) {
printf("%s: begin\n", (char *) arg);
for (int i = 0; i < 1e7; i++) {
counter = counter + 1;
}
printf("%s: done\n", (char *) arg);
return NULL;
}
//
// main()
//
// Just launches two threads (pthread_create)
// and then waits for them (pthread_join)
//
int main(int argc, char *argv[]) {
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
Pthread_create(&p1, NULL, mythread, "A");
Pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("main: done with both (counter = %d)\n", counter);
return 0;
}代码说明:
- 使用了封装函数(如
Pthread_create)以处理错误。 - 两个线程各自循环 1000 万次,每次将共享变量
counter加 1。 - 预期结果:
counter最终应为 20,000,000。
然而,实际运行结果却不可预测,且往往不正确:
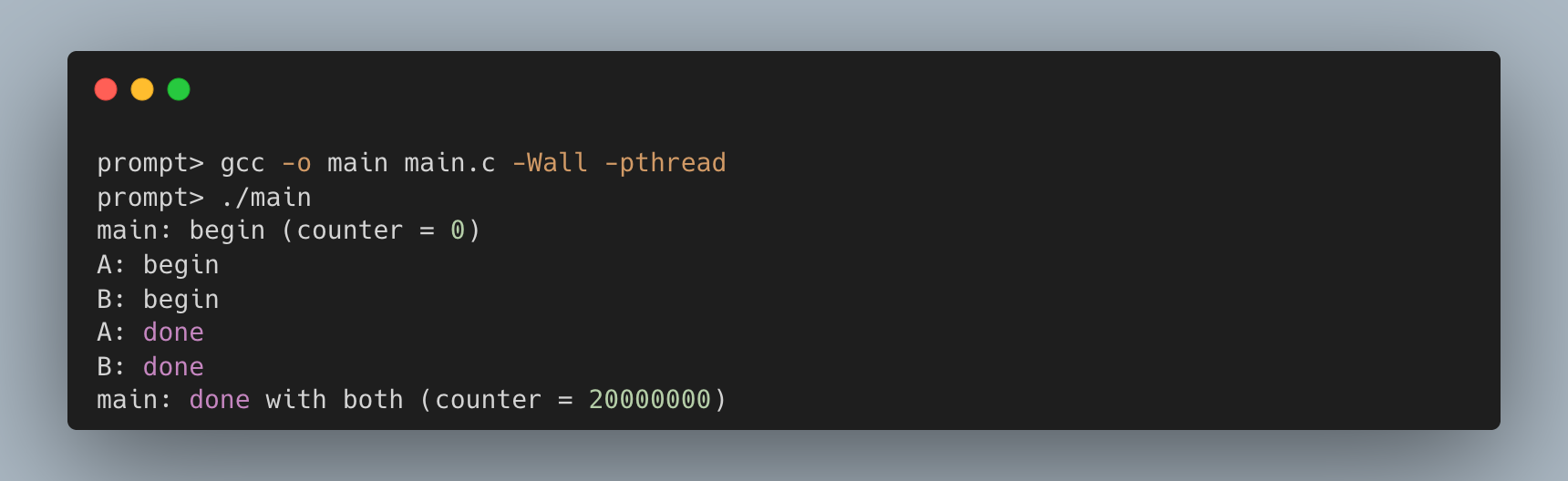
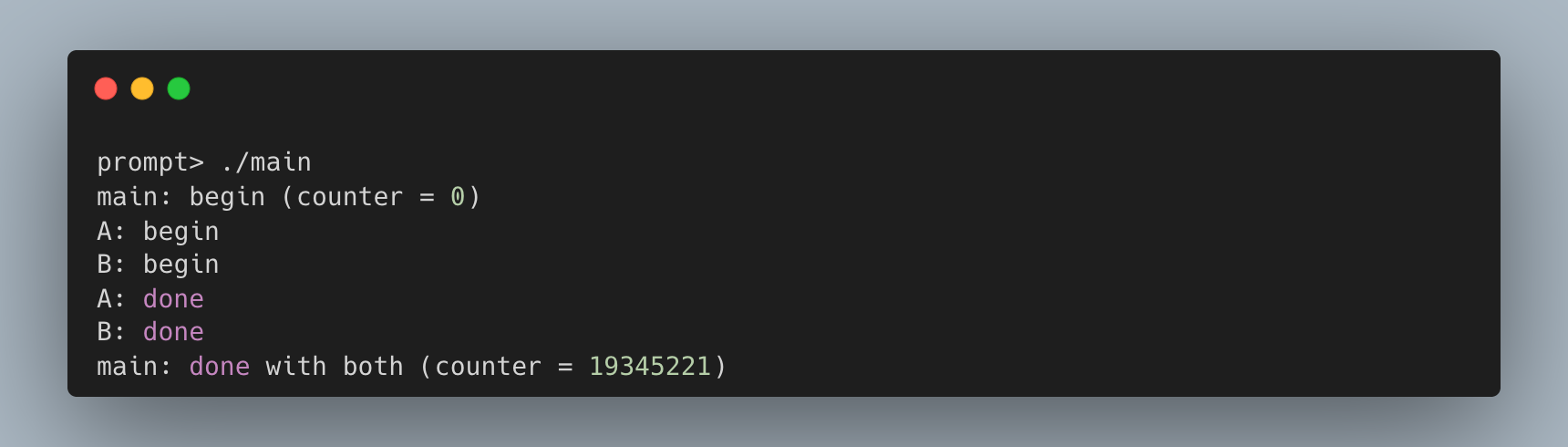
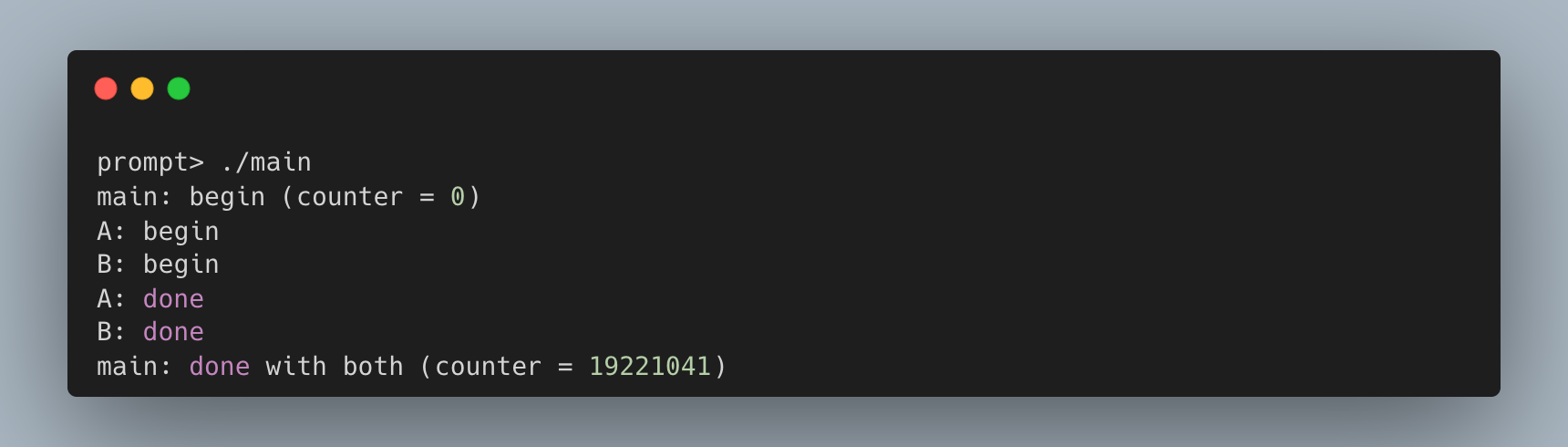
每次运行不仅结果错误,而且结果还各不相同!为什么会发生这种情况?
了解并使用工具善用工具能帮助理解系统。例如,反汇编程序(disassembler) 可以显示程序的汇编指令。
prompt> objdump -d main(Linux)可以查看更新计数器的底层汇编代码。 熟练掌握
gdb(调试器)、valgrind(内存分析器)及编译器等工具,能助你构建更好的系统。
核心问题:不可控的调度
问题根源在于 counter = counter + 1 操作并非 原子(atomic) 的。在汇编层面,它包含三个步骤:
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c 如果在指令执行间隙发生上下文切换,就会导致问题。例如:
- 线程 1 加载
counter(50) 并加 1 (51),但在写回内存前被中断。 - 线程 2 运行,加载
counter(仍为 50),加 1 并写回 (51)。 - 线程 1 恢复,将寄存器中的 51 写回内存。
结果:两次增加操作仅让
counter增加了 1(从 50 变 51,而非 52)。
这种结果取决于执行时序的情况称为竞态条件(race condition),其结果是不确定的(indeterminate)。访问共享资源的代码片段被称为临界区(critical section)。
下表展示了上述导致错误的执行轨迹:
| OS | 线程 1 | 线程 2 | PC | %eax | counter |
|---|---|---|---|---|---|
| 在临界区之前 | 100 | 0 | 50 | ||
mov 0x8049a1c, %eax | 105 | 50 | 50 | ||
add $0x1, %eax | 108 | 51 | 50 | ||
| 中断 保存 T1 的状态 恢复 T2 的状态 | 100 | 0 | 50 | ||
mov 0x8049a1c, %eax | 105 | 50 | 50 | ||
add $0x1, %eax | 108 | 51 | 50 | ||
mov %eax, 0x8049a1c | 113 | 51 | 51 | ||
| 中断 保存 T2 的状态 恢复 T1 的状态 | 108 | 51 | 51 | ||
mov %eax, 0x8049a1c | 113 | 51 | 51 |
我们要追求的是互斥(mutual exclusion):保证同一时间只有一个线程能进入临界区执行。这一概念由 Edsger Dijkstra 提出。
原子性愿望
解决竞态条件的理想方案是拥有更强大的 原子(atomic) 指令。原子意味着“作为一个单元”执行,“要么全做,要么不做”,中间不会被中断。
例如,如果硬件提供一条超级指令:
memory-add 0x8049a1c, $0x1如果硬件保证其原子性,那么更新计数器的问题就迎刃而解。
但在现实中,硬件无法为所有复杂操作(如更新 B 树)提供原子指令。因此,我们需要硬件提供一些基础的 同步原语(synchronization primitive)。结合操作系统的支持,我们可以利用这些原语构建互斥机制,从而在并发环境下安全地访问临界区。
关键并发术语
这正是并发部分要解决的核心问题:如何利用硬件和操作系统支持,构建正确的同步机制?
关键问题:如何实现同步?为了构建有用的同步原语,需要从硬件中获得哪些支持?需要从操作系统中获得什么支持?如何正确有效地构建这些原语?程序如何使用它们来获得期望的结果?
还有一个问题:等待
除了访问共享变量,线程间还存在另一种交互:等待。例如,当进程发起 I/O 请求时,它会进入睡眠状态,直到 I/O 完成被唤醒。这种“睡眠/唤醒”机制将在后续关于条件变量(condition variable)的章节中详细讨论。
小结:为什么操作系统课要研究并发
操作系统本身就是最早的并发程序。由于中断随时可能发生,内核必须小心地维护页表、进程列表、文件系统结构等共享数据。早在多线程应用出现之前,OS 设计者就必须解决这些并发更新内部结构的问题,以保证系统的正确性。
原子操作 (Atomic Operation)原子操作是构建计算机系统的基石,核心思想是“全有或全无”(All or Nothing)。无论是内存指令、文件系统日志,还是数据库事务,都依赖原子性来保证状态的一致性:操作要么全部完成,要么完全不发生,绝不会出现中间状态。