操作系统通常有两种空间管理方法:
- 分段(Segmentation):将空间分割成不同长度的分片,但会导致外部碎片问题。
- 分页(Paging):将空间分割成固定长度的分片。
在分页机制中:
- 页(Page):虚拟地址空间被分割成的固定大小单元。
- 页帧(Page Frame):物理内存被看作定长槽块的阵列,每个页帧包含一个虚拟页。
核心问题如何通过分页实现虚拟内存以避免分段的碎片问题?如何平衡其空间和时间开销?
一个简单例子
1. 概念模型
假设一个 64 字节的地址空间,包含 4 个 16 字节的页(VP 0~3)。物理内存由多个页帧(Page Frame)组成。

- 灵活性:分页不需要假定堆和栈的增长方向。
- 简单性:空闲空间管理变得容易,操作系统只需维护一个空闲页列表。
2. 页表(Page Table)
操作系统为每个进程维护一个页表,用于存储虚拟页(VP)到物理帧(PF)的地址转换关系。
- 示例映射:(VP 0 → PF 3), (VP 1 → PF 7), (VP 2 → PF 5), (VP 3 → PF 2)。
3. 地址转换流程
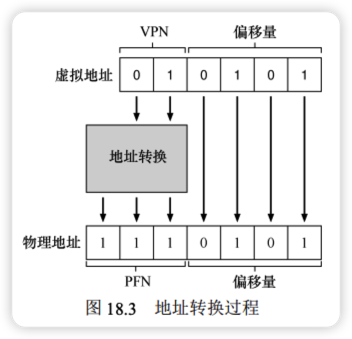
虚拟地址由两部分组成:虚拟页号(VPN)和页内偏移量(Offset)。

以虚拟地址 21(二进制 010101)为例:
- 拆分地址:前 2 位为 VPN (
01),后 4 位为 Offset (0101)。 - 检索页表:VPN
01对应 PFN111(7)。 - 组合物理地址:用 PFN 替换 VPN,偏移量保持不变。最终物理地址为
1110101(十进制 117)。
movl 21, %eax # 虚拟地址 21 -> 物理地址 117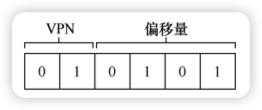
页表存在哪里
页表可能变得非常大。例如,在 32 位地址空间中,若页面大小为 4KB:
- VPN:20 位(约 100 万个条目)。
- 空间开销:若每个页表条目(PTE)占 4 字节,则每个进程的页表需 4MB 内存。若有 100 个进程,仅页表就需 400MB。
由于页表太大,无法存储在 MMU 的寄存器中,而是存储在物理内存中。

页表条目(PTE)的内容
页表是映射虚拟页号(VPN)到物理帧号(PFN)的数据结构。最简单的形式是线性页表(数组)。
1. 常见控制位
页表项(PTE)除了包含 PFN 外,还包含多个控制位:
- 有效位 (Valid Bit):指示转换是否有效。用于支持稀疏地址空间,未使用的空间标记为无效,无需分配物理帧。
- 保护位 (Protection Bit):规定页面的读、写、执行权限。
- 存在位 (Present Bit):指示该页是在物理内存还是在磁盘上(已换出)。
- 脏位 (Dirty Bit):指示页面进入内存后是否被修改过。
- 参考位 (Reference Bit):指示页面是否被访问过,用于页面替换算法。
2. x86 示例
下图展示了 x86 架构中的 PTE 结构,包含了上述位以及缓存控制位(PWT, PCD, PAT, G)和 PFN。

分页:性能挑战
分页虽然解决了碎片问题,但也带来了显著的性能开销。
1. 额外的内存访问
每次内存引用(取指或存取数据)都需要先访问一次页表以获取物理地址,这意味着工作量翻倍,可能导致系统减慢两倍或更多。
2. 地址转换逻辑
硬件通过 页表基址寄存器(PTBR) 定位页表。转换逻辑如下:
// 从虚拟地址提取 VPN 和偏移量
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
offset = VirtualAddress & OFFSET_MASK
// 形成页表项(PTE)的地址
PTEAddr = PageTableBaseRegister + (VPN * sizeof(PTE))
// 访问内存获取 PTE,并组合物理地址
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False) RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False) RaiseException(PROTECTION_FAULT)
else {
PhysAddr = (PTE.PFN << SHIFT) | offset
Register = AccessMemory(PhysAddr)
}3. 核心挑战
分页必须解决两个关键问题:
- 速度:如何避免额外的内存访问带来的巨大开销?
- 空间:如何减少页表占用的海量内存?
后续章节将讨论如何通过 TLB(转换检测缓冲区) 和 多级页表 来解决这些问题。
内存追踪:分页下的访问开销
通过一个简单的数组初始化循环来演示分页时的内存访问行为:
int array[1000];
for (i = 0; i < 1000; i++)
array[i] = 0;1. 汇编层面的操作
循环核心对应的 x86 汇编如下:
0x1024 movl $0x0,(%edi,%eax,4) # 存储 0 到 array[i]
0x1028 incl %eax # i++
0x102c cmpl $0x03e8,%eax # i < 1000 ?
0x1030 jne 0x1024 # 若不等则跳转2. 内存访问分析
假设页面大小为 1KB,页表位于物理内存。每次循环迭代产生的内存访问包括:
- 取指(Instruction Fetch):每条指令执行前,硬件必须先访问页表(1次内存访问)获取物理地址,再读取指令(1次内存访问)。
- 数据访问(Data Access):
movl指令需要额外访问一次页表(1次内存访问)来转换数组元素的虚拟地址,然后再执行实际的写入(1次内存访问)。
3. 可视化追踪
下图展示了前 5 次循环迭代的内存访问模式。可以看到,页表访问(浅灰色) 占据了相当大的比例。
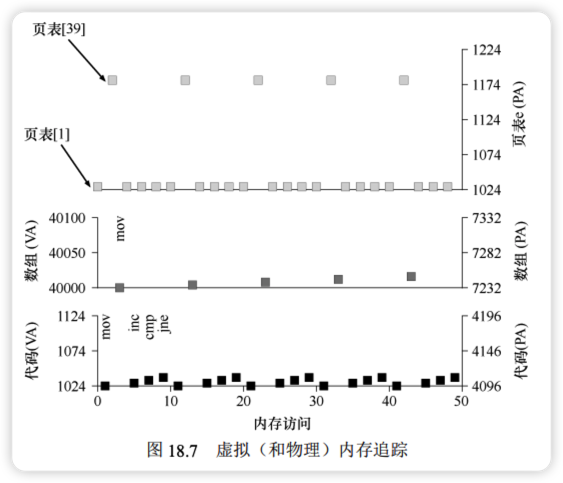
结论在没有优化的情况下,分页会导致内存访问次数翻倍,显著降低系统性能。
小结
- 优点:分页消除了外部碎片,且极其灵活,能有效支持稀疏虚拟地址空间。
- 缺点:如果不加优化,页表会占用大量内存空间,并因额外的内存访问导致系统变慢。
后续章节将介绍如何通过 TLB 解决速度问题,以及通过多级页表解决空间问题。