目前我们假设进程的地址空间必须完整且连续地加载到内存中。然而,这种简单的基址加界限机制存在显著缺陷:
- 内存浪费:地址空间中栈(Stack)和堆(Heap)之间通常存在大量未使用的空闲空间,但它们依然占用了实际物理内存,导致严重的内部碎片。
- 缺乏灵活性:如果物理内存中没有足够的连续区域来容纳整个地址空间,进程就无法运行,即使实际使用的内存很少。
核心问题:如何支持稀疏的地址空间?如何高效地支持大地址空间,同时避免为栈和堆之间大量未使用的空闲空间分配物理内存?
分段:泛化的基址/界限
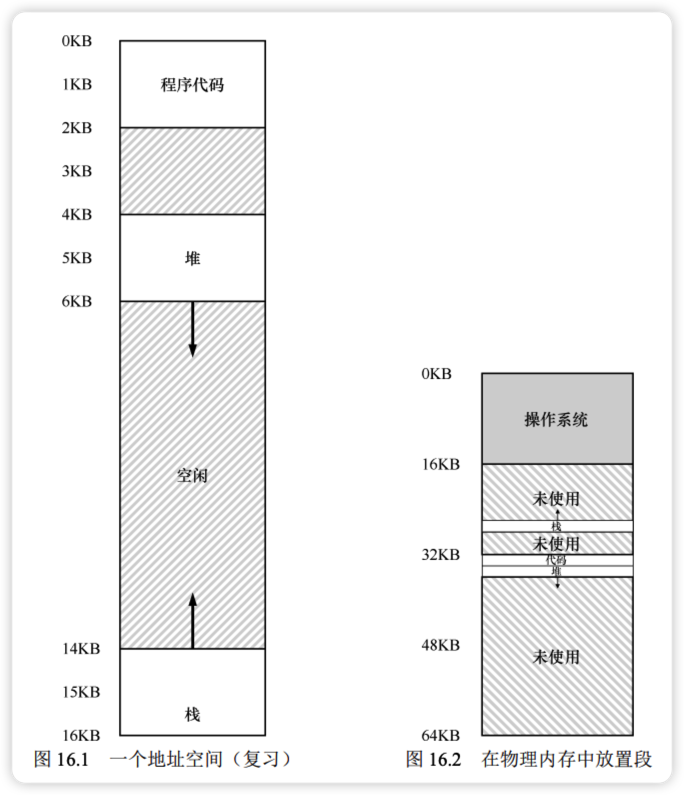
分段(Segmentation) 机制在 MMU 中为地址空间的每个逻辑段(代码、栈、堆)引入了一对独立的基址和界限寄存器。这使得操作系统能够将不同的段离散地存放在物理内存中,从而避免为未使用的虚拟地址空间分配物理内存。
例如,图 16.2 展示了将 64KB 地址空间中的三个段独立放入物理内存的情况。只有实际使用的内存才占用物理空间,支持了稀疏地址空间(Sparse Address Spaces)。
| 段 | 基址 | 大小 |
|---|---|---|
| 代码 | 32KB | 2KB |
| 堆 | 34KB | 2KB |
| 栈 | 28KB | 2KB |
地址转换示例
-
代码段:引用虚拟地址 100。
- 物理地址 = 基址 (32KB) + 偏移量 (100) = 32868。
- 检查:100 < 界限 (2KB),合法。
-
堆段:引用虚拟地址 4200。
- 堆从虚拟地址 4KB (4096) 开始,偏移量 = 4200 - 4096 = 104。
- 物理地址 = 基址 (34KB) + 偏移量 (104) = 34920。
- 检查:104 < 界限 (2KB),合法。
段错误(Segmentation Fault)如果访问非法地址(如 7KB,超出堆界限),硬件会发现越界并触发异常,导致操作系统终止进程。这就是程序员熟知的“段错误”来源。
引用段的识别机制
硬件在地址转换时需要确定虚拟地址引用了哪个段以及段内偏移量。
显式方式(Explicit Approach)
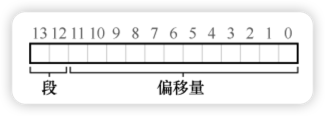
通过虚拟地址的高位(Top Bits)来标识段。例如在 14 位虚拟地址中,使用前 2 位区分段:
以虚拟地址 4200 为例,其二进制形式如下:
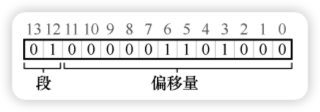
- 段标识:前 2 位(
01)指向堆段。 - 段内偏移:后 12 位(
0000 0110 1000,即 104)作为偏移量。
硬件逻辑伪代码如下:
// 获取 14 位虚拟地址的高 2 位作为段索引
Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
// 获取偏移量
Offset = VirtualAddress & OFFSET_MASK
if (Offset >= Bounds[Segment])
RaiseException(PROTECTION_FAULT)
else
PhysAddr = Base[Segment] + Offset
Register = AccessMemory(PhysAddr)栈的处理与反向增长
栈(Stack)在地址空间中通常是反向增长的。为了支持这种特性,硬件需要额外的一位来标识段的增长方向。
| 段 | 基址 | 大小 | 增长方向 (1=正向, 0=反向) |
|---|---|---|---|
| 代码 | 32KB | 2KB | 1 |
| 堆 | 34KB | 2KB | 1 |
| 栈 | 28KB | 2KB | 0 |
反向地址转换示例
假设访问虚拟地址 15KB(二进制 11 1100 0000 0000):
- 段标识:前两位
11指向栈段。 - 偏移量计算:
- 原始偏移量为 3KB(15KB - 12KB 栈起始)。
- 反向偏移 = 原始偏移量 - 段最大长度 = 3KB - 4KB = -1KB。
- 物理地址 = 基址 (28KB) + 反向偏移 (-1KB) = 27KB。
- 界限检查:确保反向偏移的绝对值(1KB)小于段大小(2KB)。
支持共享与保护
随着分段机制的演进,设计者意识到通过增加硬件支持可以实现更高的效率。其中最关键的应用场景是代码共享(Code Sharing)。在现代系统中,运行同一程序的多个实例(如多个编辑器窗口或 shell)非常常见。通过共享只读的代码段,系统可以大幅节省内存,而无需为每个进程存储重复的代码副本。
保护位(Protection Bits)
为了支持共享,硬件为每个段增加了保护位,标识程序是否能够读、写或执行该段。
| 段 | 基址 | 大小 | 增长方向 (1=正向, 0=反向) | 保护权限 |
|---|---|---|---|---|
| 代码 | 32KB | 2KB | 1 | 读—执行 |
| 堆 | 34KB | 2KB | 1 | 读—写 |
| 栈 | 28KB | 2KB | 0 | 读—写 |
通过将代码段标记为“只读”和“可执行”,物理内存中的同一个段可以安全地映射到多个虚拟地址空间。虽然每个进程都认为自己独占这块内存,但操作系统通过保护位确保了进程无法修改共享内容,从而在维持隔离假象的同时实现了高效共享。
引入保护位后,硬件在地址转换时不仅要进行界限检查,还必须进行权限检查。如果进程试图执行未授权的操作(如向只读的代码段写入数据),硬件将触发异常。
粗粒度与细粒度分段
分段的粒度决定了系统管理内存的灵活性:
粗粒度(Coarse-grained)分段
将地址空间划分为少数几个较大的块(如代码、栈、堆)。这是我们之前讨论的主要方式。
细粒度(Fine-grained)分段
允许将地址空间划分为大量较小的段(如成千上万个段)。
- 硬件支持:需要更复杂的 段表(Segment Table) 来存储大量段的元数据。
- 优势:编译器可以将代码和数据进一步细分,使操作系统能更精确地掌握内存使用情况,从而显著提升内存利用率。
操作系统支持:挑战与应对
分段机制虽然节省了内存,但也给操作系统带来了新的管理负担:
- 上下文切换:操作系统必须在进程切换时,保存和恢复每个进程的一组段寄存器。
- 空闲空间管理与外部碎片:由于每个段的大小不同,物理内存很快会充满许多细小的空闲间隙,导致无法分配较大的连续空间。这种现象称为外部碎片(External Fragmentation)。
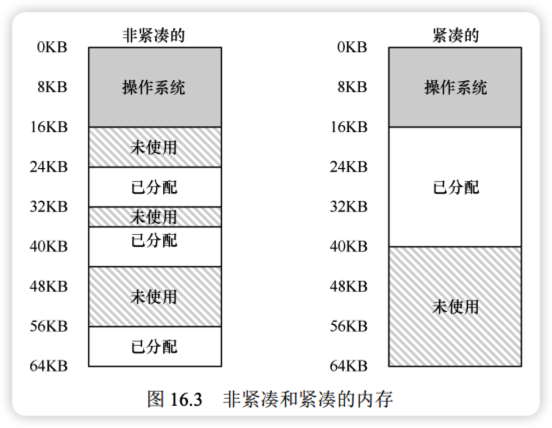
解决外部碎片的方案:
- 内存紧凑(Compaction):操作系统通过停止进程并拷贝数据,将原有的段重新排列成连续区域。
- 缺点:内存拷贝是计算密集型操作,会占用大量 CPU 时间,成本极高。
- 空闲列表管理算法:利用各种算法(如最优匹配 Best-fit、最坏匹配 Worst-fit、首次匹配 First-fit 等)试图减少碎片。
- 局限性:无论算法多精妙,都无法完全消除外部碎片,只能尽量减小。
根本解决之道存在成百上千种碎片管理算法,正说明了没有完美的解决方案。真正的解决办法是完全避免分配不同大小的内存块,这正是我们后续将讨论的**分页(Paging)**机制的核心思想。
小结
分段机制通过将地址空间划分为逻辑段,显著提升了虚拟内存的效率:
-
优点:
- 支持稀疏地址空间:避免了栈和堆之间大量空闲空间的内存浪费。
- 性能高效:地址转换逻辑简单,硬件开销极小。
- 支持代码共享:通过保护位实现跨进程的代码段共享。
-
局限性:
- 外部碎片:由于分配的段大小不一,物理内存会被割裂成难以利用的小块。
- 无法处理极稀疏的段:如果某个逻辑段(如堆)本身非常大且稀疏,分段机制仍要求将其完整加载到内存中。
分段虽然迈出了一大步,但仍无法完美解决所有内存虚拟化问题。为了应对这些根本性的挑战,我们需要一种更灵活的机制:分页(Paging)。