在内存充裕时,处理页错误只需从空闲列表中分配页面。但当内存不足产生 内存压力 (Memory Pressure) 时,操作系统必须通过 替换策略 (Replacement Policy) 决定 踢出 (Evict) 哪些页面,以腾出空间给活跃进程。
关键问题:如何决定踢出哪个页?操作系统通过替换策略决定踢出哪些页面。该策略通常遵循通用原则,并针对特殊情况进行微调。
内存作为缓存 (Memory as Cache)
由于内存容量有限,它实际上是所有虚拟页面的 缓存。策略目标是 最小化缓存未命中 (Cache Miss),从而降低 平均内存访问时间 (AMAT)。
- :访问内存成本(约 100ns)
- :访问磁盘成本(约 10ms)
- 关键点:磁盘访问极慢,即使微小的未命中率(如 1%)也会导致 AMAT 显著增加,严重拖慢系统性能。
缓存未命中的三种类型 (The 3 C's)计算机体系结构中常将未命中分为三类:
- 强制性未命中 (Compulsory Miss):也称冷启动未命中 (Cold-start Miss)。由于缓存开始为空,页面的第一次访问必然未命中。
- 容量未命中 (Capacity Miss):由于缓存空间不足,必须踢出旧页面以容纳新页面,导致后续访问旧页面时未命中。
- 冲突未命中 (Conflict Miss):由于硬件缓存的组相联 (Set-associativity) 限制,多个地址映射到同一位置导致的未命中。操作系统页缓存通常是全相联 (Fully-associative) 的,因此不存在此类未命中。
替换策略演进 (Replacement Policies)
1. 最优策略 (The Optimal/MIN Policy)
- 核心思想:替换 最远将来 才会被访问的页。
- 原理:既然该页在最远的将来才会被访问,踢出它能最大限度推迟下一次未命中的发生。
- 作用:不可实现(操作系统无法预知未来的访问序列),仅作为 性能上限 的对比基准。如果一个新策略的命中率接近 MIN,说明它已经非常完美。
表 22.1 追踪最优策略 (命中率 54.5%)
| 访问 | 命中/未命中 | 踢出 | 缓存状态 | 说明 |
|---|---|---|---|---|
| 0, 1, 2 | 未命中 | 0, 1, 2 | 冷启动 | |
| 0, 1 | 命中 | 0, 1, 2 | ||
| 3 | 未命中 | 2 | 0, 1, 3 | 预测 2 在最远将来才被访问(优于踢出 0 或 1) |
| 0, 3, 1 | 命中 | 0, 1, 3 | ||
| 2 | 未命中 | 3 | 0, 1, 2 | 预测 3 不再被访问 |
| 1 | 命中 | 0, 1, 2 |
2. 简单策略 (FIFO & Random)
- FIFO (先进先出):
- 机制:维护一个队列,踢出最早进入队列的页。
- 缺陷:无法识别页面重要性(可能踢出频繁访问的重要页面)。
- Belady 异常:对于 FIFO,增加缓存大小有时反而导致命中率下降(因为它不具备栈特性)。
- Random (随机):
- 机制:随机选择一个页面踢出。
- 特点:实现简单,无状态。虽然性能波动大(看运气),但避免了 FIFO 在特定序列下的病态最差表现。
表 22.2 追踪 FIFO 策略 (命中率 36.4%)
| 访问 | 命中/未命中 | 踢出 | 缓存状态 | 说明 |
|---|---|---|---|---|
| 0, 1, 2 | 未命中 | 0, 1, 2 | 0 为队头 | |
| 0, 1 | 命中 | 0, 1, 2 | ||
| 3 | 未命中 | 0 | 1, 2, 3 | 踢出队头 0 |
| 0 | 未命中 | 1 | 2, 3, 0 | 刚踢出 0 又访问 0(FIFO 的典型失败) |
| 3 | 命中 | 2, 3, 0 | ||
| 1 | 未命中 | 2 | 3, 0, 1 | 刚踢出 1 又访问 1 |
| 2 | 未命中 | 3 | 0, 1, 2 | 刚踢出 2 又访问 2 |
| 1 | 命中 | 0, 1, 2 |
3. 基于历史的策略 (LRU)
为了克服简单策略的盲目性,我们需要利用 历史访问信息。
- 局部性原则 (Principle of Locality):
- 时间局部性:最近访问过的页,不久后很可能再次访问。
- 空间局部性:访问某页后,其附近的页很可能被访问。
- LRU (Least-Recently-Used):替换 最近最少使用 的页。
- LFU (Least-Frequently-Used):替换 最不经常使用 的页。
表 22.4 追踪 LRU 策略 (命中率 54.5%)
| 访问 | 命中/未命中 | 踢出 | 缓存状态 | 说明 |
|---|---|---|---|---|
| 0, 1, 2 | 未命中 | 0, 1, 2 | LRU: 0 | |
| 0, 1 | 命中 | 2, 0, 1 | LRU: 2 (0, 1 刚被访问) | |
| 3 | 未命中 | 2 | 0, 1, 3 | 踢出 LRU 2 |
| 0, 3, 1 | 命中 | 0, 3, 1 | LRU: 0 | |
| 2 | 未命中 | 0 | 3, 1, 2 | 踢出 LRU 0 |
| 1 | 命中 | 3, 2, 1 |
工作负载对比 (Workload Analysis)
通过三种典型负载考察策略表现:
-
无局部性 (No Locality):随机访问 100 个页。
- 表现:LRU、FIFO、Random 表现一致。命中率完全取决于缓存大小。
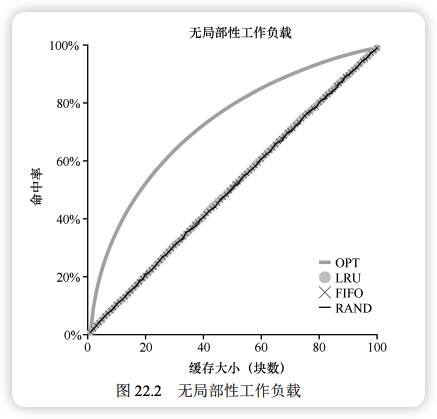
- 表现:LRU、FIFO、Random 表现一致。命中率完全取决于缓存大小。
-
80-20 负载 (Locality):20% 的热点页占据 80% 的访问。
- 表现:LRU 最佳,因为它能牢牢保留热点页。FIFO 和 Random 可能错误地踢出热点页。
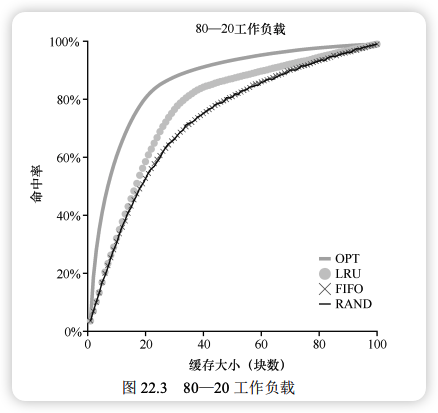
- 表现:LRU 最佳,因为它能牢牢保留热点页。FIFO 和 Random 可能错误地踢出热点页。
-
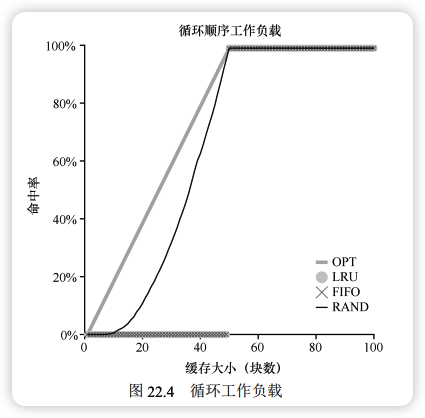
循环扫描 (Looping):顺序循环访问 50 个页 (0…49, 0…49…)。
- 表现:LRU 和 FIFO 最差 (0% 命中)。当缓存大小为 49 时,它们总是踢出马上要访问的页(最旧的页)。
- Random:表现更稳健,避免了这种病态情况。
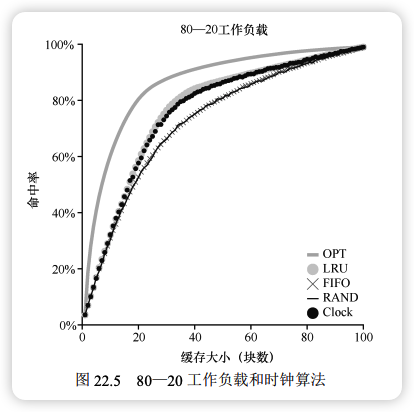
实现与优化 (Implementation)
近似 LRU:时钟算法 (Clock Algorithm)
实现完美的 LRU 需要在每次内存访问时更新数据结构(如移动链表节点),硬件开销过大。现代系统使用 引用位 (Use Bit / Reference Bit) 实现近似 LRU。
- 机制:
- 所有页组成一个循环列表,操作系统维护一个 时钟指针 (Clock Hand)。
- 硬件支持:每当页面被访问(读或写),硬件自动将该页的 引用位设为 1。
- 替换逻辑:当需要替换页时,扫描指针指向的页:
- 若引用位为 1:表示最近被使用过。操作系统 将引用位清零 (设为 0),并将指针移向下一页(给予该页“第二次机会”)。
- 若引用位为 0:表示最近未被使用(且已经过了一轮扫描),直接踢出该页。
脏页优化 (Dirty Pages)
- 脏页 (Modified/Dirty):被修改过的页。踢出时必须写回磁盘,I/O 成本高昂。
- 干净页 (Clean):未被修改的页。踢出时无需 I/O(物理帧可直接重用)。
- 策略:引入 修改位 (Dirty Bit)。时钟算法优先踢出 既未使用又干净 的页,显著降低磁盘 I/O。
系统级问题
- 抖动 (Thrashing):当内存需求远超物理内存时,系统不断进行换页,导致 CPU 忙于等待 I/O,几乎不执行有效工作。
- 对策:准入控制 (暂停部分进程以减小工作集) 或 OOM Killer (杀死内存密集型进程)。
- 预取 (Prefetching):操作系统猜测即将访问的页(如顺序读取时的 P+1 页)并提前载入。
- 聚集写入 (Clustering):将多个小的写操作合并为一次大的写操作,提高磁盘带宽利用率。